JRuby: Using Celluloid concurrency library to utilize full CPU multithreading and convert a large JSON file to CSV
In this tutorial I’ll demo some JRuby code that uses a fantastic concurrency library Celluloid, to utilize full CPU multithreading and convert a large JSON file to CSV. Celluloid really shines with implementations of Ruby that are not limited by the GIL like JRuby and Rubinius.
Created a Gemfile. Execute “bundle install” to install.
source 'https://rubygems.org'
gem 'celluloid'I executed the following script to create a 1GB file consisting of JSON hashes with a randomized order of defined keys.
#!/usr/bin/env jruby
# require ruby libs
require 'securerandom'
require 'json'
# define a list of hash keys
known_fields = ['address_1', 'address_2', 'city', 'state', 'zip']
# define output file
file_name = 'big_file.txt'
# populate file
file = File.open(file_name, 'w')
while file.size <= 1073741824
data = {}
# randomize key order
known_fields.shuffle.each do |field|
data[field] = SecureRandom.hex
end
file.write(data.to_json + "\n")
end
file.closeI used the linux “split” command to chunk the 1GB file into 50k line files, prefixed with “_split_”.
split -l 50000 big_file.txt _split_The following class includes the Celluloid library and implements methods to read a file, parse the JSON, convert the data to an array of known fields, and write to CSV.
#!/usr/bin/env jruby
# require ruby libs/gems
require 'celluloid'
require 'json'
require 'csv'
# define a list of hash keys
known_fields = ['address_1', 'address_2', 'city', 'state', 'zip']
split_file_prefix = "_split_"
# get a list of files to process
file_list = Dir.glob("#{split_file_prefix}*")
file_list.delete_if {|f| f =~ /\.csv$/}
raise "No files to process." if file_list.empty?
# define celluloid worker class
class Worker
# read the source/wiki. fibers/threads/magic.
include Celluloid
# main method to process file. read, convert, write.
def process_file(file_name=nil, known_fields=[])
# validation
raise "File name required." if file_name.nil? || file_name.empty?
raise "Known fields list required." if known_fields.nil? || known_fields.empty?
# do work
data = read_json_file(file_name, known_fields)
write_csv_file("#{file_name}.csv", data)
true
end
private
# read JSON file, iterate lines, convert each JSON to array
def read_json_file(file_name, known_fields)
raise "File does not exist: #{file_name}" unless File.exists?(file_name)
ret = []
File.open(file_name, "r") do |f|
f.each_line do |line|
result = json_line_to_array(line, known_fields)
ret << result unless result.nil?
end
end
ret
end
# take a json string, parse, collect known fields data
def json_line_to_array(line=nil, known_fields)
return nil if line.nil?
begin
json_data = JSON.parse(line)
rescue
return nil
end
ret = []
known_fields.each do |field|
if json_data.has_key?(field)
ret << json_data[field]
else
ret << nil
end
end
ret
end
# write out array of fields to CSV
def write_csv_file(file_name, data)
raise "Data invalid" if data.nil? || data.empty?
CSV.open(file_name, "a") do |csv|
data.each {|d| csv << d}
end
end
end
# define worker pool
pool = Worker.pool
# iterate/process files
futures = file_list.map do |file|
pool.future.process_file(file, known_fields)
end
futures.map(&:value)As you can see in the above class, there is no mention of fibers, threads, or java.util.concurrent; just: include Celluloid. In this example, I chose to implement a Celluloid pool which uses the futures method to queue tasks.
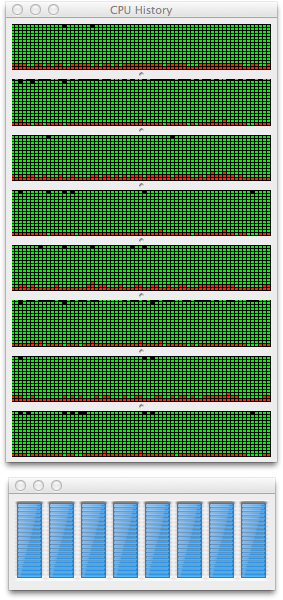
Execute the above script and you’ll notice via Java VisualVM (jvisualvm) and Activity Monitor full CPU core utilization. Get your money’s worth out of your multi-core system.