Using Nifi to convert CSV to JSON and store in Elasticsearch
In this post I’ll share a Nifi workflow that takes in CSV files, converts them to JSON, and stores them in different Elasticsearch indexes based on the file schema. I created a JRuby ExecuteScript processor to use the header row of the CSV file as the JSON schema, and the filename to determine which index/type to use for each Elasticsearch document.
For this post I used homebrew on OSX, but you could use Docker, install from source, etc.
Example install:
# ex: install/start elasticsearch
brew install elasticsearch
brew services start elasticsearch
# browse to http://localhost:9200
# ex: install/start nifi
brew install nifi
export NIFI_HOME="/usr/local/Cellar/nifi/1.5.0/libexec"
$NIFI_HOME/bin/nifi start
# browse to http://localhost:8080/nifi/My planned Nifi workflow:
- Get a list of CSV files from a local directory
- ExecuteScript processor to convert them to JSON, use the header row as the JSON schema, and set index/type attribute on each flow file
- SplitJson processor to convert JSON array of objects to individual JSON records
- PutElasticsearch processor to send to Elasticsearch, routed to index/type based on flow file attribute
Screenshot of workflow:
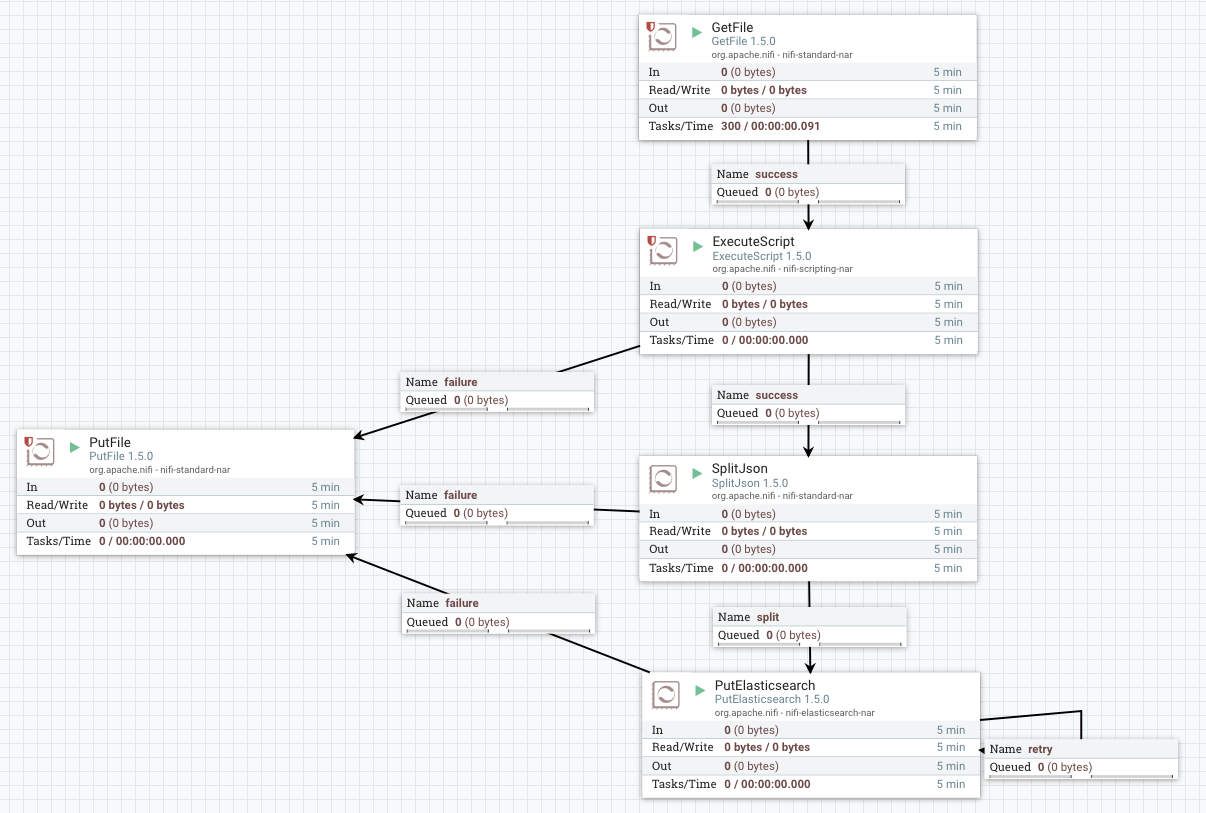
1. GetFile
- Input directory: /nifi/in/
- File filter:
[^\.].*\.csv$
2. ExecuteScript
- Script engine: ruby
- Script file: /nifi/scripts/csv_to_json.rb
Contents of /nifi/scripts/csv_to_json.rb:
java_import org.apache.commons.io.IOUtils
java_import java.nio.charset.StandardCharsets
java_import org.apache.nifi.processor.io.StreamCallback
require 'csv'
require 'fileutils'
require 'json'
require 'logger'
class FileStreamCallback
include StreamCallback
def process(in_stream, out_stream)
# read file as text
text = IOUtils.toString(in_stream, StandardCharsets::UTF_8)
# parse CSV, convert to JSON using header row
csv_data = CSV.parse(text)
header_row = csv_data.shift
json_data = csv_data.map {|row| Hash[header_row.zip(row)] }
json_string = json_data.to_json
# rewrite file as json string
out_stream.write(json_string.to_java.getBytes(StandardCharsets::UTF_8))
end
end
flowfile = session.get()
if flowfile.nil?
return
end
# setup logger
log_path = '/nifi/logs/'
log_file = 'csv_to_json.log'
FileUtils.mkdir_p(log_path) unless File.directory?(log_path)
$logger = Logger.new("#{log_path}#{log_file}")
# ensure we only process csv files (note: this is redundant)
filename = flowfile.getAttribute('filename')
if filename !~ /\.csv$/
$logger.warn("File extension must be csv: #{filename}")
session.transfer(flowfile, REL_FAILURE)
return
end
begin
# create a new StreamCallback instance and write to flow file
stream_callback = FileStreamCallback.new
flowfile = session.write(flowfile, stream_callback)
# update filename extension
new_filename = filename.gsub(/\.csv$/, '.json')
flowfile = session.putAttribute(flowfile, 'filename', new_filename)
# set index/type
index_type = /^(.*)\.json$/.match(new_filename)[1].downcase
index_type = /^(.*?)_part/.match(index_type)[1] if index_type =~ /_part/
flowfile = session.putAttribute(flowfile, 'index_type', index_type)
$logger.info("file: #{filename}; new file: #{new_filename}; index_type: #{index_type}")
session.transfer(flowfile, REL_SUCCESS)
rescue => e
$logger.error(e)
session.transfer(flowfile, REL_FAILURE)
end3. SplitJson
- Converts JSON array of objects to individual objects
- JsonPath Expression:
$.*
4. PutElasticsearch
- Cluster name: elasticsearch
- ElasticSearch Hosts: localhost:9300
- Identifier Attribute: uuid
- Index:
${index_type} - Type:
${index_type}
Note: cluster name must match Elasticsearch server configuration, ex:
grep -i cluster.name /usr/local/etc/elasticsearch/elasticsearch.yml
cluster.name: elasticsearch
5. PutFile
- Used for failure connections
- Directory: /nifi/errors/
- Conflict Resolution Strategy: replace
- Create Missing Directories: true
I create some scripts to generate data, ex:
#!/usr/bin/env ruby
require 'csv'
require 'faker'
PEOPLE_COUNT = 1_000
ROWS_PER_FILE = 50
file_counter = 0
csv_data = []
people = (1..PEOPLE_COUNT).map do |id|
if csv_data.size == 0
csv_data << %w(id first_name last_name email)
end
csv_data << [
id,
Faker::Name.first_name,
Faker::Name.last_name,
Faker::Internet.email
]
# note: this does not check last iteration
if csv_data.size > ROWS_PER_FILE
file_counter += 1
file_name = "people_part_#{file_counter}.csv"
CSV.open("./#{file_name}", "wb") do |csv|
csv_data.each do |c|
csv << c
end
end
csv_data = []
end
endI executed the data creation scripts, and then copied the CSV files into the input directory, ex: cp /nifi/data/*.csv /nifi/in/
Contents of the ExecuteScript log file:
tail -f /nifi/logs/csv_to_json.log
I, [2018-03-04T10:23:28.763877 #75354] INFO -- : file: people_part_2.csv; new file: people_part_2.json; index_type: people
I, [2018-03-04T10:23:28.779399 #75354] INFO -- : file: people_part_13.csv; new file: people_part_13.json; index_type: people
I, [2018-03-04T10:23:28.797090 #75354] INFO -- : file: products_part_15.csv; new file: products_part_15.json; index_type: products
I, [2018-03-04T10:23:28.805136 #75354] INFO -- : file: products_part_4.csv; new file: products_part_4.json; index_type: products
I, [2018-03-04T10:23:28.822709 #75354] INFO -- : file: products_part_9.csv; new file: products_part_9.json; index_type: products
I, [2018-03-04T10:23:28.832498 #75354] INFO -- : file: products_part_10.csv; new file: products_part_10.json; index_type: products
I, [2018-03-04T10:23:28.855308 #75354] INFO -- : file: people_part_12.csv; new file: people_part_12.json; index_type: people
I, [2018-03-04T10:23:28.870675 #75354] INFO -- : file: people_part_20.csv; new file: people_part_20.json; index_type: people
I, [2018-03-04T10:23:28.879414 #75354] INFO -- : file: people_part_4.csv; new file: people_part_4.json; index_type: people
I, [2018-03-04T10:23:28.887039 #75354] INFO -- : file: products_part_8.csv; new file: products_part_8.json; index_type: productsInspecting data in Elasticsearch:
curl 'http://localhost:9200/people/_search?pretty&size=1'
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1000,
"max_score" : 1.0,
"hits" : [ {
"_index" : "people",
"_type" : "people",
"_id" : "d49a4a19-48ed-47c5-b855-a18f798d0ce0",
"_score" : 1.0,
"_source" : {
"id" : "8",
"first_name" : "Eric",
"last_name" : "London",
"email" : "eric.london@example.com"
}
} ]
}
}